Feature Engineering, Supervised and Unsupervised Learning with Parsa Vafaie - IMI BIGDataAIHUB Technical Workshops

On January 19, the 2022-2023 IMI BIGDataAIHUB’s Case Competition’s fourth Technical Workshop was led by Scotiabank’s Parsa Vafaie. The workshop demonstrated how to utilize supervised and unsupervised machine learning, and how to engineer features aligned with business needs.
The Learning Process & Demonstrations
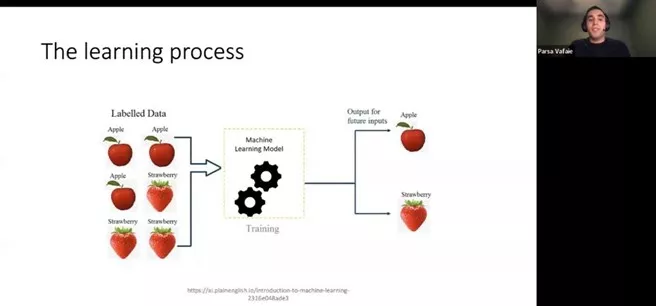
The workshop began with a high-level overview of the learning process. The process begins by inputting labeled data. From there, machines are trained through a machine-learning model to identify and classify data. Finally, the machine produces outputs for future inputs. For additional details visit this page on an introduction to machine learning.
In the real world, the process is much more complex. Normal datasets require a significant time investment to clean up the data. The majority of the work is done on data processing. Features must be engineered based on the business needs. Whenever we train a classifier or train a model, explainability is extremely important. Always try to see what the most important features are in the classifier, and to see if it makes sense with the business needs.
Through the discussion about supervised learning, Parsa first demonstrated how to use the role translation data and engineering features to it. After adding features, Parsa went through the machine learning process where he trained and tested the learning. From there, he reviewed the graphs that were created and developed edge features from the graph. Additional features can also be created, for instance, the sum of transactions, average transactions, and average neighborhood.
Manifold Learning
A manifold learning is a strategy to address non-linear dimensionality reduction. Algorithms for this approach are founded on the idea that the dimensionality of many data sets is artificially high. See this resource for more information. Parsa suggested using the T-distributed Stochastic Neighbor Embedding (TSNE) method. To learn more about the TSNE manifold learning approach visit this page here. Parsa noted that it is a good method to start your data visualization. Furthermore, Parsa advised sampling your data first, because if you are working with a large dataset the process will be very slow. Additionally, the data should be normalized first.
Combining Supervised and Unsupervised Learning
Doing unsupervised learning is also very important, for instance, whenever you have transactional and customer features, it is always a good thing to do a clustering to see if you have any specific customer profiles. Based on specific customer profiles, labels can be put on top of the customer profiles to determine if there is any correlation with the actual labels. Sometimes this strategy can improve the results of the supervised learning. Therefore, whenever you have labels, don’t rule out unsupervised learning, because it can be a very useful tool.
Additional Resources
Parsa suggested using the following packages to streamline these processes for the case competition participants: PyTorch Geometric, Pandas-profiling, and Imbalanced-learn. PyTorch Geometric has sophisticated models, and it is easy to work with, however, graph models will require a lot of memory. Pandas-profiling can help see how transactions are distributed. Imbalanced-learn helps when sampling imbalanced data, samplings can be used to train better models – particularly for the task involving bad actors. To understand graph neural networks, visit this page, which shows basic and sophisticated methods. Once you get an understanding of these methods, they can be useful for the case competition scenario as well.
Parsa emphasized that visualization is the most interesting part of data science, and it helps to understand data even better. These strategies shared throughout the fourth technical workshop will be immensely helpful when completing the case competition deliverables, and beyond.